Scaled Dot Product Attention
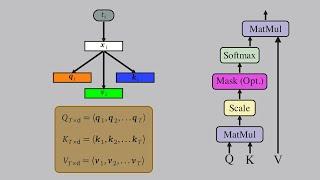

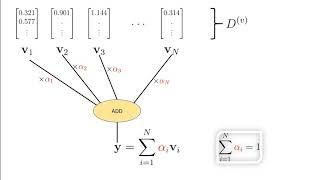
The math behind Attention: Keys, Queries, and Values matrices
Serrano.Academy
66K
220,355
10 месяцев назад

1A - Scaled Dot Product Attention explained (Transformers) #transformers #neuralnetworks
Prabhjot Gosal
2K
5,094
2 года назад


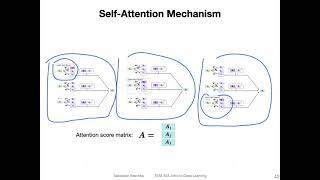
Self-attention mechanism explained | Self-attention explained | scaled dot product attention
Unfold Data Science
350
1,166
1 месяц назад

Rasa Algorithm Whiteboard - Transformers & Attention 2: Keys, Values, Queries
Rasa
23K
76,445
4 года назад

10 ML algorithms in 45 minutes | machine learning algorithms for data science | machine learning
Unfold Data Science
81K
269,917
1 год назад

Attention in transformers, visually explained | Chapter 6, Deep Learning
3Blue1Brown
394K
1,314,808
3 месяца назад


CS480/680 Lecture 24: Gradient boosting, bagging, decision forests
Pascal Poupart
2K
7,111
4 года назад



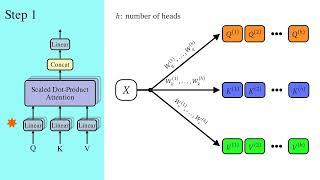
A Dive Into Multihead Attention, Self-Attention and Cross-Attention
Machine Learning Studio
7K
23,032
1 год назад

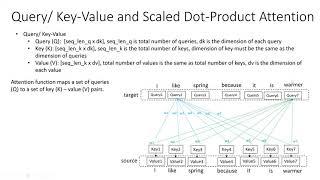
How to explain Q, K and V of Self Attention in Transformers (BERT)?
code_your_own_AI
3K
10,581
1 год назад

Attention Mechanism - Basics, Additive Attention, Multi-head Attention
Bytes of CSE
264
881
8 месяцев назад



Pytorch for Beginners #29 | Transformer Model: Multiheaded Attention - Scaled Dot-Product
Makeesy AI
378
1,261
2 года назад



Transformer Attention is all you need | Scaled dot Product Attention models | Self Attention Part 1
Ligane Foundation
118
393
3 года назад

Multi-head attention | Scaled dot Product Attention | Transformers attention is all you need |Part 2
Ligane Foundation
140
465
3 года назад

Сейчас ищут
Scaled Dot Product Attention
The Texas Chain Saw Massacre Ps5
Premiere Rush Video Editing
Dual Pc Setu
Easy Macrame Plant Hanger
Ufc Recap
Loft Storage
Creating And Displaying Your First Ad With Advanced Ads
Ipl Cricket
Ad Items
Baleno Cng Mileage Comparison
Walking Nature
Simple Asmr
Sons Of The Forest Black Screen
Hijjaj Bin Yousuf Death
Switchrpg
Length Check Javascript
Dispatch Live 18
Autofilter By Color
Learn Leverage Trading
Php Fetch All
Pediatric Mri
New Disney World 2024
Documentary Photo
Dragons Dogma 2 80 Seekers Tokens
Certify Breakfast
Set Controls For Android Game In Bluestacks 5
Firmware Flash S8
Pteradon
Атмосфернаямузыка
Fix A Golf Slice
Monogram Logo Illustrator
Scaled Dot Product Attention смотреть видео. Рекомендуем посмотреть видео Self-Attention Using Scaled Dot-Product Approach длительностью 16:09. Invideo.cc - смотри самые лучшие видео бесплатно